
Abnormal Psychology
Personality Psychology
Clinical Psychology
Cognitive Psychology
Social Psychology
Industrial Organizational Psychology
Criminal Psychology
Counselling Psychology
Assessment in Psychology
Indian Psychology
Health Psychology
健康心理学
健康心理学 (jiànkāng xīnlǐ xué)
Ethics in Psychology
Statistics in Psychological
Specialized Topics in Psychology
Media Psychology
Peace Psychology
Consumer Psychology
- Dystonia: Causes & Treatment
- Zero Stroke: Meaning & Causes
- Subnormal, Supernormal and Paranormal in Abnormal Psychology
- Meaning of 4 D’s in Abnormal Psychology
- International Classification of Diseases
- Insanity Defense: Meaning & Applicability
- Wernicke-Korsakoff Syndrome
- Vertigo: Symptoms, Causes, and Treatments
- Transvestic Disorder
- Quadriplegia
- Myotonia Congenita
- Lafora Disease
- Prosopagnosia
- Microcephaly
- Macrocephaly
- Lissencephaly
- Isodicentric 15
- Dysautonomia
- Double Vision
- Developmental Coordination Disorder
- Dawson Disease
- Dandy-Walker Syndrome
- Palinopsia
- Angelman Syndrome
- Alien Hand Syndrome
- Sexual Sadism Disorder
- Sexual Masochism Disorder
- Parkinson’s Disease
- Cyclic Vomiting Syndrome
- Craniosynostosis
- Confusional Arousals
- Rapid Eye Movement Sleep Behavior Disorder
- Corticobasal Degeneration
- Coma: Symptoms & Causes
- Color Blindness
- Cognitive Model of Abnormal Psychology
- Zellweger Syndrome
- Hypoxia
- Hypersomnia: Meaning & Symptoms
- Coffin-Lowry Syndrome
- Cockayne Syndrome
- Cluster Headache
- West Syndrome
- Voyeuristic Disorder
- Sleep-Related Eating Disorders
- Sleep Related Movement Disorders
- Pyromania
- Psychotic Major Depression
- Psychodynamic Model of Abnormal Psychology
- Pedophilia: A Disorder of Sexual Attraction For Minors
- Olfactory Reference Syndrome
- Neuroticism: Meaning and Effect
- Neurogenetic Disorders
- Narcolepsy: A Sleep Disorder
- Kleptomania: Symptoms & Causes
- Intermittent Explosive Disorder
- Insomnia: A Sleep Disorder
- Hypoesthesia
- Fragile X Syndrome
- Fibromyalgia
- Febrile Seizures
- Fahr’s Syndrome
- Extraversion Vs. Introversion: Hans Eysenck
- Encephalitis
- Dyskinesia
- Dysgraphia
- Cocaine Induced Anxiety
- Chronic Fatigue Syndrome
- Chorea
- Cerebral Arteriosclerosis
- Cerebral Aneurysm
- Cephalic Disorder
- Centronuclear Myopathy
- Central Pontine Myelinolysis
- Central Pain Syndrome
- Causalgia
- Carpal Tunnel Syndrome
- Canavan Disease
- Brody Myopathy
- Brain Death
- Attention Deficit Hyperactivity Disorder
- ATR-16 Syndrome
- Ataxia
- Asomatognosia
- Arachnoiditis
- Apraxia: A Neurological Disorder
- Aphasia: Spoken Language Disorder
- Akinetopsia: A Disorder of Motion Blindness
- Aicardi Syndrome
- Agraphia: Lost of Writing Skill
- Agnosia: A Disorder of Memory Loss
- Achromatopsia: A Disorder of Color Vision
- Abulia: A Neurological Disorder
- Genito-pelvic Pain/penetration Disorder
- Frotteurism Disorder
- Exhibitionistic Disorder
- Avoidant/Restrictive Food Intake Disorder
- FIRO-B
- Aphantasia
- Anosognosia: A Disorder of Loss of Insight
- Oppositional Defiant Disorder
- Kleine- Levin Syndrome
- Internet Gaming Disorder
- Inhalant-Related Psychiatric Disorders
- Encopresis (Involuntary Defecation)
- Atypical Depression
- Synthetic cathinone-induced Psychotic Disorder
- Reactive Attachment Disorder
- Insufficient Sleep Syndrome
- Disinhibited Social Engagement Disorder
- Corticobasal Syndrome
- Amnesia: A Mental Disorder of Forgetting Things
- Traumatic Brain Injury
- Trance and Possession Disorder
- Sedative, Hypnotic, or Anxiolytic Induced Psychotic Disorder
- Premature Ejaculation
- Enuresis (Involuntary Urination)
- Exploding Head Syndrome
- Common Defense Mechanisms Used for Anxiety
- Caffeine-Induced Anxiety Disorder
- Benzodiazepine-Induced Mood Disorders
- Alcohol-Induced Mood Disorders
- Non-24-Hour Sleep-Wake Disorder
- Mild Neurocognitive Disorder
- Jet Lag
- Cocaine-Induced Psychosis
- Amphetamine-Induced Psychosis
- Cannabis-Induced Psychosis
- Psychological Disorders: Meaning and Types
- Prolonged Grief Disorder
- Partial Dissociative Identity Disorder
- Models of Abnormal Psychology
- Mental Health Vs. Mental Illness
- Dissociative Amnesia with Dissociative Fugue
- Behavior Model of Abnormal Psychology
- Biological Model of Abnormal Psychology
- Schizotypal Personality Disorder
- Stigma Around Substance Abuse Disorder
- Schizophreniform Disorder
- Schizoid Personality Disorder
- Obsessive-Compulsive Personality Disorder
- Coping with Stress
- Avoidant Personality Disorder
- Antisocial Personality Disorder
- Histrionic Personality Disorder
- Drug Use Disorders
- Dependent Personality Disorder
- Borderline Personality Disorder
- Paranoid Personality Disorder
- Nightmare Disorder
- Personality Stability and Change
- Paraphilic Disorders
- Gender Dysphoria
- Pica: Causes, Symptoms, & Treatment
- Motor Disorder
- Gambling Disorder
- Female Orgasmic Disorder
- Erectile Disorder
- Disruptive Impulse Control and Conduct Disorders
- Dementia: Symptoms and Causes
- Delirium: Meaning & Symptoms
- Conduct Disorder
- Anxiety: A Threat to the Ego
- Alzheimer’s Dementia
- Alcohol Use Disorder
- Vascular Dementia
- Narcissistic Personality Disorder
- Lewy Body Dementia
- Huntington’s Disease
- ChildhoodOnset Fluency Disorder (Stuttering)
- Speech Sound Disorder (Phonological Disorder)
- Sleepwake Disorders
- NonRapid Eye Movement Sleep Arousal Disorders
- Elimination Disorders
- Attention Deficit/Hyperactivity Disorder: A Spinning Top
- Gender Differences in Schizophrenia
- Neurodevelopmental Risk Factors in Schizophrenia
- Developmental Processes in Schizophrenic Disorders
- Schizophrenia Symptoms: Positive and Negative?
- Schizophrenia: Meaning, Symptoms & Treatment
- Suicide: Definition and Meaning
- Seasonal Affective Disorder (S.A.D.)
- Learning Disorders
- Language Disorders
- Catatonia: Meaning & Treatment
- Persistent Delusional Disorder
- Male Hypoactive Sexual Desire Disorder
- Brief Psychotic Disorder (BPD)
- Female Sexual Interest/Arousal Disorder (FSIAD)
- Schizoaffective Disorder
- Rumination Disorder
- Grief and Trauma Counselling
- Fetal Alcohol Syndrome
- Restless Legs Syndrome
- Various Types of Mood Disorders
- Bulimia Nervosa
- Bipolar II Disorder
- Bipolar I Disorder
- Binge Eating Disorder
- Separation Anxiety Disorder (SAD)
Personality Psychology
- Kretschmer’s Classification
- Metamotivation: Meaning and Significance
- Three Essays on The Theory of Sexuality
- The Psychopathology of Everyday Life
- Criticisms of Carl Roger’s Theory
- Aspects of Personality: Carl Jung
- Feminist Perspective on Erikson’s Theory
- Gender Identity and Sexual Orientation in Erickson’s Theory
- Self-Actualization: Meaning & Significance
- Rogers’ Humanist Theory of Personality
- Raymond Cattell’s Theory of Personality
- Personality Development in Childhood: The Unique Self
- Gordon Allport: As a Psychologist
- The Decline and Fall of the Freudian Empire
- Television Violence and Aggressive Behaviour: Albert Bandura
- Anticipating Life Events: George Kelly
- Person-Centered Therapy: Carl Rogers
- Biological Theory of Intelligence: Hans Eysenck
- Generativity vs. Stagnation: Erik Erikson
- Emotional Adjustment: Meaning and Significance
- Eysenck’s Pen Model of Personality
- Criticism of Allport’s Trait Theory of Personality
- Criticism of Freud’s Psychoanalysis
- Harmony Between Personalities
- Carl Rogers: As a Psychologist
- Albert Bandura: As a Psychologist
- Trust vs Mistrust: Erik Erikson
- Reinforcement Theory of Motivation – B. F. Skinner
- Reinforcement and Punishment: B.F. Skinner
- Oedipus Complex and Electra Complex
- Neuroticism vs. Emotional Stability
- Mother -Infant Bonding: Allport’s Theory
- Eysenck’s Personality Theory
- Cultural Differences in Facial Expression: Allport’s Theory
- Initiative vs. Guilt: Erik Erikson
- Industry vs. Inferiority: Erik Erikson
- George Kelly: A contemporary Psychologist
- Erik Erikson’s Stages of Psychosocial Development
- Erikson’s Identity Development Theory
- Erik Erikson: As A Psychologist
- Self-Report Personality Tests
- Personality Traits and Personality Types
- Identity Cohesion vs. Role Confusion
- Intimacy vs. Isolation: The Importance of Relationships
- Freudian Slip
- Extensions of Freudian Theory
- Autonomy Vs. Doubt and Shame: Erik Erikson
- Role of Culture in the Development of Personality
- Research in Personality
- Personal Construct Theory: George Kelly
- NEO Five-Factor Inventory
- B. F. Skinner: As a Psychologist
- Striving for Superiority
- Basic Anxiety: The Foundation of Neurosis
- Karen Horney: As a Psychologist
- Limitations and Criticism of Alder’s Theory
- Creative Power of the self: Alfred Adler
- Alfred Adler’s Personality Theory
- Carl Jung: Balance of Personality
- Birth Order & Child Personality
- Inferiority Complex: Alfred Adler
- Adlerian Theory vs. Freudian Theory
- Adlerian Theory in Psychology
- Weaknesses of Carl Jung’s Theory
- The Jungian Model of Psyche
- Psychosexual Stages of Personality Development
- Carl Jung Vs Freud
- Assessment in Freud’s Theory
- The Role of Social Media on Personality
- The Interpretation of Dreams: Sigmund Freud
- Personality Assessment
- Development of Personality by Carl Jung
- Assessment of Personality by Carl Jung
- Anna Freud and Ego Psychology
- Animal Models of Personality and Cross-Species Comparison
- Alfred Adler: Individual psychology
- Alfred Adler: As a Phycologist
- Carl Jung’s Personality Theory
- Personality Development and Training
- Stable Personality Trait
- An Indian Perspective to Personality
- Crime and Personality
- Analytical Psychology: Definition and Meaning
- Types of Psychological Test
- Role of Gender and Race in Shaping Personality
- Standardized Psychological Tests
- Relationship Between Personality and Emotions
- Indian Triguna Personality An Indian Lens on Personality
- Id, Ego, and SuperEgo
- Ethical Issues in Personality Assessment
- Concept of Self in Different Tradition
- Carl Jung and Sigmund Freud
- Social Cognitive Theory of Personality
- Semi Projective Tests
- Thematic Apperception Test
- FiveFactor Model of Personality: McCrae & Costa
- Difference Between Freudian and Neo Freudian Theories
- Rorschach Inkblot Test
- Psychometric Theories of Intelligence
- Psychological Attributes: Meaning & Characteristics
- Personality: Definition & Meaning
- Personality Assessment: Meaning and Methods
- Modern Psychometric Theories
- Intelligence Tests: Nature & Classification
- Intelligence Tests: Meaning & Significance
- Information Processing Theories of Intelligence
- Individual Variation: Meaning & Causes
- Individual Differences: Meaning and Causes
- Humanistic Approach to Personality: Meaning & Types
- Human Intelligence: Meaning and Definition
- Emotional Intelligence: Meaning & Significance
- Culture and Intelligence
- Cultural and Personality
- Behavioral Analysis of Personality
- Behavioral Theory and Personality
- Assessment of Pscyhological Attributes
- Aptitude: Meaning and Assessment
Clinical Psychology
- Type of Therapists
- Treatment of Psychological Disorders
- Research Methods in Clinical Psychology
- Indigenous Therapies: Meaning & Application
- Group Therapy: Meaning & Significance
- Differences Between Individual, Group, and Couples Therapy
- Current Problems of Clinical Psychology in India
- Clinical Social Work: Meaning & Significance
- Clinical Judgement: Meaning & Significance
- Career in Clinical Psychology
- Trauma Systems Therapy: Meaning And Application
- Cognitive Behaviour Therapy: Meaning And Application
- Humanistic-Existential Therapy: Meaning And Application
- Forensic Psychotherapy: Meaning and Types
- Eclectic Psychotherapy: Meaning And Significance
- Child Psychotherapy: Meaning And Significance
- Nature and Process of Psychotherapy
- Difference Between Psychologists and Therapists
- History of Clinical Psychology
- Clinical Psychology: Meaning and Significance
- Acceptance and Commitment Therapy: Meaning And Application
- Art Therapy: Meaning & Significance
- Sexual Trauma Therapy: Meaning And Application
- Remote Therapy: Meaning & Benefits
- Parent-Child Interaction Therapy: Meaning And Application
- Gay Affirmative Therapy: Meaning And Application
- Biomedical Therapy: Meaning And Application
- Occupational Therapy: Meaning And Application
- Writing Therapy: Meaning And Application
- Yoga Therapy: Meaning and Application
- Client-Centered Therapy: Meaning and Application
- Gestalt Therapy: Meaning and Application
- Behavioural Therapy: Meaning and Application
- Alternative Therapy: Meaning & Types
- The Difference Between Counselor, Psychologist, & Psychiatrist
- ClientTherapist Relationship: What Are the Boundaries?
Cognitive Psychology
- Visual Word Recognition: Meaning of Application
- Interface Between Syntax-Semantic
- Perception of Speech: Meaning & Application
- Syntax and Production of Language
- Syntax Parsing: Meaning & Significance
- Spoken Word Recognition: Meaning & Application
- Lexical Sorting and Sentence Context Effect
- Figurative Language: Meaning & Significance
- Eye Motion Control in Reading
- Discourse Comprehension: Meaning & Significance
- Structure of Human Language
- Schachter-Singer Theory of Emotion
- Linguistic Hierarchy
- Properties of Human Language
- Latent Learning
- Cannon-Bard Theory of Emotion
- Theories of Selective Attention
- Broadbent’s Filter Model
- The Brain: Anatomy and Function
- The Multimode Model of Attention
- Recognition by Components Theory
- Helmholtz Theory
- Pandemonium Architecture
- Factors Affecting Memory Recall
- Theories of Motivation
- Psychological and Physiological Bases of Motivation and Emotion
- Theories of Emotion
- Interrelation Between Language and Thought in Humans
- Factors Influencing Intrinsic Motivation
- Biological Bases of Emotions
- Operant Conditioning Theory
- Observational Theory of Learning
- Deutsch-Norman Memory Model of Attention
- Classical Conditioning Theory
- B.F. Skinner’s Theory of Language Development
- Behaviorists Theory of Learning
- Auditory Attention: Meaning And Significance
- Visual Imagery: Meaning And Significance
- Treisman’s Attenuation Model
- Trace Decay Theory of Forgetting
- Theories of Decision Making
- Escape Learning: Meaning And Significance
- Social Intelligence: Meaning And Application
- Self-Instructional Learning: Meaning And Significance
- Schedule of Reinforcements
- Programmed Learning: Meaning And Significance
- Process of Concept Formation
- Probability Learning: Meaning And Significance
- Piaget’s Theory of Cognitive Development
- Creative Thinking: Meaning And Significance
- Perceptual Organization: Meaning And Significance
- Fostering Creativity: How to Develop Creativity?
- Extrasensory Perception: Meaning And Significance
- Escape Learning Vs. Avoidance Learning
- Avoidance Learning: Meaning And Significance
- Approach to Pattern Recognition
- Subitizing: Meaning and Significance
- Reasoning and Problem Solving
- Plasticity of Perception: Meaning And Significance
- Biological Factors Influencing Perception
- Bilingualism: Meaning And Significance
- Size Estimation: Meaning And Significance
- Perceptual Readiness: Meaning And Significance
- Factors Influencing Attention
- Attention vs. Perception
- Repression Theory of Forgetting
- Process of Extinction
- Parallel Distributed Processing Model
- Language Acquisition: Meaning And Significance
- Displacement Theory: Meaning And Application
- Interference Theory of Forgetting: Meaning And Application
- Inductive Vs. Deductive Reasoning
- Consolidation Theory
- ACT Model: Meaning And Application
- The Concept of Threshold
- Signal Detection and Vigilance
- Sensation: Meaning and Significance
- Process and Types of Communication
- Factors Influencing Decision Making
- Depth Perception: Meaning And Significance
- Types of Emotions
- The Cognitive Revolution in Psychology
- Split Brain: Meaning And Significance
- Sensory Memory: Meaning And Significance
- McGurk Effect: Meaning And Application
- Instinct: Meaning & Theories
- Cognitive Psychology: Definition and Meaning
- Attention: Definition and Meaning
- Attention Span: Meaning And Significance
- Top-Down Approach Vs. Bottom-Up Approach
- Lateralization of Brain Functions
- Iconic Memory: Meaning And Significance
- Facilitating and Hindering Factors in Problem Solving
- Echoic Memory: Meaning And Significance
- Divided Attention: Meaning And Application
- Attention Shifting: Meaning And Significance
- Levels of Processing Model
- Organization and Mnemonic Techniques
- Multi-Store Model of Memory: Meaning And Significance
- Meta-Memory: Meaning And Significance
- Absolute Threshold Vs. Difference Thresholds
- Eyewitness Memory
- Autobiographical Memory
- Anterograde and Retrograde
- Optical Illusion
- Synesthesia
- Subliminal Perception
- Perception: Definition and Meaning
- Memory Improvement
- Transpersonal Psychology
- Reconstructive Memory
- Inattentional Blindness
- Cognitive Maps
- Brain Behavior Relationship
- Aneurysm
- Working Memory
- Proactive and Retroactive Interference
- Long Term Memory
- Encoding and Remembering
- Synaptic Connection
- Transforming Problems
- Problem Solving: Meaning, Theory, and Strategies
- Mnemonic Device
- Means-ends Analysis
- Barriers to Problem Solving
Social Psychology
- Violence and the Media
- The Violence Around Us
- Meaning of Social Group in Psychology
- Personal and Cultural Influences on Aggression
- Meaning of Individual and Group Interaction in Psychology
- Meaning of Conflict and Cooperation in Psychology
- Theories of Attitude
- Biological and Emotional Causes of Aggression
- Reducing Discrimination
- Other Determinants of Helping
- Measurement of Interests
- Measurement of Attitude
- Cooperative Strategy
- Conformity Theory
- Components of Attitude
- Cognitive Dissonance Theory
- Aggression: Meaning & Characteristics
- Group Process: Meaning & Characteristics
- Altruism: Meaning & Characteristics
- The Social Self
- Role of Affect: Emotions and Mood
- Social Categorization and Stereotyping
- Person, Gender, and Cultural Differences in Conformity
- Measurement of Value
- Initial Impression Formation
- Ingroup Favoritism and Prejudice
- Changing Attitudes through Persuasion
- Values: Definition and Meaning
- The Cognitive Self
- Social Diversity: Meaning & Characteristics
- Obedience: Meaning and Characteristics
- Interests: Definition and Meaning
- Group Polarization: Meaning & Applicability
- Group Polarization vs Groupthink
- Group Decision Making
- Emotions, Stress and Well-Being
- Coping with Negative Emotions
- Conformity: Meaning & Significance
- Compliance: Meaning & Significance
- Theory of Planned Behavior
- Strategies for Fostering Values
- Social Role Theory: Meaning & Characteristics
- Social Representation Theory: Meaning & Applicability
- Social Influence: Meaning & Types
- Social Identity Theory: Meaning & Applicability
- Self-Control Theory: Meaning & Applicability
- Pro-Social Behaviour: Meaning & Characteristics
- Interpersonal Attraction and Relationship
- Impression Formation: Meaning & Significance
- Group Behaviour: Meaning and Characters
- Prejudice and Discrimination
- Persuasion: Meaning & Principles
- Influence of Cultural Factors in Socialization
- Formation of Stereotypes and Prejudices
- The Balance Theory of Attitude
- Attribution Theory by Weiner
- Attribution Theory by Kelly
- Attribution Theory by Davis and Jones
- Attribution theory by Heider
- Attitude Behavior Relationship
- Social Psychology: Meaning & Theories
- Social Perception: Meaning & Theories
- Social Dominance Theory: Meaning and Significance
- Social Cognitive Theory: Meaning & Significance in Social Context
- Social Cognition: Meaning & Significance
- Self-Determination Theory: Meaning & Features
- Obedience Theory
- Fundamental Attribution Error
- Attitude: Meaning and Functioins
- Attitude Change
Industrial Organizational Psychology
- Self Determination Theory: Meaning & Application
- Indian Theory of Leadership: Meaning & Application
- Behavioral Theory of Leadership: Meaning & Application
- Work-Life Balance: Meaning & Significance
- Training and Human Resource Development: Meaning & Application
- Participative Leadership: Meaning & Significance
- Trait Theory of Leadership: Meaning & Significance
- Power in an Organization: Meaning & Significance
- Politics in an Organisation: Meaning & Significance
- Management Training Methods: Meaning & Application
- Job Design: Meaning & Significance
- Employee Selection Process: Meaning & Application
- Work Motivation: Meaning & Significance
- Perceived Organizational Support (POS)
- Organisational Citizenship Behavior
- Managerial Effectiveness: Meaning and Applicability
- Human Factors and Ergonomics
- Transactional Leadership Theory
- Training Model: Meaning & Application
- Sensitivity Training: Meaning and Significance
- McClelland Theory of Motivation
- Job Satisfaction Theories
- Goal Setting Theory of Motivation
- Employee Engagement: Meaning & Significance
Criminal Psychology
- Theories of Criminality
- Hering’s Opponent Color Theory
- Decision-Making in the Courtroom
- Analysis of the Criminal Justice System
- The Social Reality of Crime
- Serial Killings in India
- Role of Forensic Psychology in Criminal Justice
- Reliability and Validity of Forensic Science Evidence
- Psychological Approaches to Detection of Deceit
- Mob Psychology and Crowd Control
- Investigative Psychology: Definition and Meaning
- Investigative Hypnosis: Meaning & Significance
- Investigating the Eyewitness: Accuracy and Fallacies of Memory
- Distinction Between Forensic and Therapeutic Evaluation
- Cybercrime: Meaning and Causes
- Serial Killer: Meaning and Types
- Violence and Mental Illness
- Juvenile Delinquency: Causes and Prevention
- How to Become a Forensic Psychologist
- How to Become a Criminal Psychologist?
- Gender and Crime
- Criminal Profiling
- Role of Criminal Psychologist
- Criminal Psychology Vs Forensic Psychology
- Realistic Group Conflict Theory
- Neutralization and Drift Theory
- Marxist Theory of Criminology
- Famous Criminal Psychologists
- Criminal Behavior Theories
- Strain Theory
- Social Disorganization Theory
- Labelling Theory
- Glenn D Walter’s Theory
- Sheldon’s Constitutional Theory
- Chromosomal Theory of Inheritance
- Bowlbys Theory of Maternal Deprivation
- Biosocial Theories of Crime
Counselling Psychology
- Career Counselling: Meaning and Significance
- Application of Counselling
- History of Counselling Psychology
- Ethics in Psychotherapy
Assessment in Psychology
- Assessment in Forensic Settings
- Psychodiagnostics Evaluation and Assessment
- Performance Appraisal
- Eyewitness Assessment and Testing
- Errors in Assessment
- Assessment Tools Used in Clinical Settings
- Assessment Centres
- Patterns of Test Operation in Clinical Assessment
- ICT in Assessment and Evaluation
- Educational Diagnosis and Assessment
- Assessment Procedure of Elderly
- Assessment of the Mental Disorders in the Elderly
- Assessment in the Teaching–Learning Process
- Utility of Psychological Assessments
- Utility Analysis
- Norms of Psychological Tests
- Need Assessment
- Item Characteristic Curve
- Interpretation of Test Scores
- Gender and Need Assessment in Sectoral Areas
- Test Bias with Minority Group
- Assessments in Organizations
- Problems with Reliability and Validity
- Employee Assessment
- Computer-Assisted Assessment
- Assumptions in Psychological Testing and Assessment
- Issue of Faking in Psychological Assessment
- Steps to Development of a Scientific Test
- Quality-of-Life Assessment
- Normal Positive Functioning
- Assessment for Treatment, Planning, Monitoring and Outcome
- Writings the Test Items in Psychology
- Validity of a Psychological Test
- Types of Validity
- Test Development
- Test Administration
- Scales of Measurement
- Reliability Measures: Meaning and Methods
- Psychological Testing and Industrial Application
- Psychological Testing and Assessment: An Overview
- Psychological Assessments: Who, What, Why, How, and Where
- Psychological Assessment Tools
- Neuropsychological Impairment: Screening and Assessing
- Neuropsychological Examination
- Neuropsychological Assessment of Infants and Young Children
- Mental Status Examination
- Intelligence Testing and Its Issues
- Historical Perspective of Psychological Assessment
- Elements of Psychological Testing: Construction, Administration, & Interpretation
- Culture and Assessment
- Clinical Interview: Meaning and Types
- Case History for Diagnosis
- Career Choice and Transition Assessment
- Behaviour Assessment: Meaning and Types
- Assessment of Intelligence
Indian Psychology
- Transpersonal Psychology: Definition and Meaning
- Scope and Research in Indian Psychology
- Models of Personality in Buddhist Psychology
- Mind: Nature, States and Functions
- Indian Perspectives on Happiness
- Identity and Self in Indian Thought
- Ayurveda: Healing and Pedagogy
- Sufi Psychology: Definition and Meaning
- Sufi Path to Self-Transformation
- The Secret of the Veda by Sri Aurobindo
- Spiritual Climate in Business Organizations
- Psychology of Consciousness in Sankya Yoga
- Mind and Language: A Indian Perspective
- Meditation in the Indian Context
- Concept of Dharma
- Yoga and Western Psychology
- Knowledge: According to Aurobindo
- Theoretical Bases of Spiritual Psychology
- The Seer and the Seen
- Role of Yoga in Improving Mental Health and Well-being
- The Manovigyan: Ancient Indian Understanding of Psychology
- Integral Education: An Application of Indian Psychology
- Spiritual Psychology
- Sense of Insecurity and Search for God
- Raja Yoga and Psychology
- Psychotherapy and Integral Yoga Psychology
- Psychology of Vipassana Meditation
- Psychiatry and Indian Thought
- Yoga Sutras of Patanjali
- Karma Yoga and Positive Psychology
- Modern Indian Psychology Development
- Integral Education in the Indian Context
- Indian Psychology: Possible Hypotheses
- Indian Psychology: Implications and Applications
- Indian Perspectives on Knowledge
- Indian Meditation: Meaning and Therapeutic Applications
- Historical and Cultural Background of Spiritual Counselling
- Genesis and Development of Teacher Education in India
- Social and Personal Transformation: A Gandhian Perspective
- Gandhi: An Organization Guru
- Indian Meditation: Global Effects
- Difference Between Western and Indian Psychology
- Basic Principles of Patanjali’s Philosophy
- Application of Pratyahara
- Gyana Yoga: Definition and Meaning
- Gradients of Consciousness
- Components and Levels of Mind as Per Yoga
- Spirituality in India
- The Science of Kundalini
- The Mirambika Experience
- Psychotherapy and Indian Thought
- Psychological Disorders and the Indian Culture
- Indian Psychology in the New Millennium
- Indian Psychology and the Scientific Method
- History of Indian Psychology
- Healing and Counselling in the Traditional Spiritual Setting
- Extra-Ordinary Human Experience: Indian Psychological Perspective
- Emotions in the Indian Thought Systems
- The History and Evolution of the Indian Education System
- Understanding Mind in Indian Philosophy
- Types of Yoga: A Psychological Perspective
- Emotions and Culture
- Pratyahara: A Useful Tool of Mental Health Management
- Bhakti Yoga: Definition and Meaning
- Beyond Mind: The Future of Psychology
Health Psychology
- Role of Positive Emotions
- Yoga & Health
- Venues of Health Habit Modification
- Factors Affecting Positive Health
- Subjective Well-Being: Meaning & Significance
- Social Relationships and Health: Meaning & Significance
- Resilience: Meaning & Significance
- Relaxation Techniques: Meaning & Significance
- Relapse Prevention Techniques: Meaning & Application
- Nutrition and Health: Meaning & Significance
- Negative Emotions: Meaning & Significance
- Health Promoting Behaviors: Meaning & Significance
- Health and Well-Being: Meaning & Significance
- Fight or Flight Response: Meaning & Significance
- Protection Motivation Theory: Meaning & Application
- Positive Health: Meaning & Significance
- Ill-Health: Meaning & Causes
- Happiness Disposition: Meaning and Significance
- Biopsychosocial Model of Health: Meaning & significance
- Biomedical Model of Health: Meaning and Significance
- Stress and Health: Meaning & Significance
- Sleep Health: Meaning & Significance
- Placebo Effect: Meaning and Significance
- Pain and Personality
- Lifestyle Disease: Meaning & Types
- Lifestyle and the Quality of Life
- Invisible Illness: Meaning & Types
- Hypertension: Causes, Symptoms, and Treatment
- Hospice Care: Meaning and Significance
- Phases of Grief by Kubler- Ross
- Self-Regulation in Health Behaviour
- Religion and Coping with Health-Related Stress
- ERG Theory in Psychology
- Changing Health Behaviour through Social Engineering
- Health Psychologist: Role and Responsibilities
- Mind-Body Connection
- Health Psychology: Definition and Meaning
- Stressor: Meaning and Its Management
- Cognitive Appraisal and Stress
- Stress Management
- Yoga For Stress
- Sources of Stress
- Stress: Meaning & Type
健康心理学
- 慢性病的情感方面
- 急性疼痛和慢性疼痛的区别
- 死亡教育:意义和重要性
- 冠心病:原因,症状和治疗。
- 跨理论模型:意义和重要性
- 理性行为理论在健康心理学中的应用
- 社会健康模式:意义与重要性
- 健康的心理模型:意义和重要性
健康心理学 (jiànkāng xīnlǐ xué)
Ethics in Psychology
- The Mental Health Business: Money and Managed Care
- Relationships with Colleagues, Students, and Employees
- Managing Challenges with Difficult Situations and Clients
- Confidentiality, Privacy, and Record-Keeping
- Attraction, Romance, and Sexual Intimacies with Clients and Subordinates
- UGC Guidelines and Educations in India
- Technology and Ethics
- Socially Sensitive Research
- Mental Health Professionals and the Legal System: Tort and Retort
- Managed Care and Ethics
- Making Ethical Decisions and Taking Action
- Ethics in Teaching, Training, and Supervision
- Ethics in Small Communities
- Ethics and Culture
- Workplace Challenges: Juggling Porcupines
- Self-Promotion in the Age of Electronic Media
- Scope of Ethics: Moral, Social, Religious, and Political
- Informed Consent: Meaning and Problems
- History of Animal Research
- Laws Relating to Psychology in India
- Ethical Issues and Their Management in India
- General Principles of American Psychological Association
- American Psychological Association and Ethical Codes
- Ethical Standards in India and Other Countries
- Problems and Ethical Issues in Counselling Practice
- Ethical Challenges in Working with Human Diversity
- Domains of Ethics: Academics, Research, and Practice
- Practising Skills for Research
- Testing the Vulnerable Groups
- Psychological Research with Human Participants
- Psychological Research with Animals
- Psychology Research Ethics
- Rehabilitation Council of Indian Rules and Codes
- Need for Appropriate Norms in Psychological Testing
- Nature of Ethics
- History of Human Experimentation
- Ethics in Rural Psychology
- Therapy and Research with Mentally Challenged: Ethical Guidelines
- Ethical Issues in Health Research and Therapy in Children
- Ethics in Psychology: Meaning and Application
- Research Ethics: Meaning and Application
- Ethical Consideration & Issues in Psychology Research
- Ethical Principles of Counselling
- Code of Ethics: Meaning and Application
Statistics in Psychological
- Application Understanding P-Values Technique in Psychology
- Appliation of Regression Analysis Psychology
- Role of Post Hoc comparisons in Research Psychology
- Role of N-way Analysis of Variance in Research Psychology
- Meaning & Application of Null Hypothesis in Psychology
- Application of Normal Probability Distribution Technique in Psychology
- Application of Item Response Theory in Psychology
- Application of Chi-Square Test in Psychology
- Application of Variance and Standard Deviation in Psychology
- Application of Z-score in Psychology
- Application of Selection Model in Psychology
- Application of Sampling Distribution Methods in Psychology
- Role of Statistical Inference in Psychology
- Role of Hypothesis Testing in Psychology
- Concept of Alternative Hypothesis in Psychology
- Measures of Variability in Research Psychology
- Measures of Central Tendency in Research Psychology
- Application of Mean, Median, and Mode of Grouped Data in Psychology
Specialized Topics in Psychology
- Emotion Vs. Mood
- Biofeedback Therapy: Meaning & Significance
- Behavioral Psychology: Meaning & Theories
- Applied Psychology: Definition and Meaning
- Anti-psychiatry: Definition and Meaning
- Biopsychology: Meaning & Significance
- Psychology of Terrorism: Definition and Meaning
- Forensic Psychology: Meaning & Application
- Consumer Psychology: Meaning & Significance
- Understanding Small Group in Social Action
- Social, Cultural, Economic, and Physical Consequences of Impoverished Groups
- Relative and Prolonged Deprivation: Meaning & Theory
- Educating and Motivating the Disadvantaged Individuals
- Vocational Guidance and Career Counselling
- Improving Memory for Better Academic Achievement
- Psychological Principals for Teaching-Learning Process
- Value Education and Personality Development
- Learning Style: Meaning & Significance
- Effective Strategies in Guidance Programs
- Educational Psychology: Meaning & Significance
- Psychological Test Used in Educational Institutions
- Group Decision-Making and Leadership for Social Change
- Effective Strategies for Social Change
- Community Psychology: Meaning & Application
- Arousing Community Consciousness
- Organising Services for Rehabilitation
- Role of Psychologist in Social Reintegration
- Rehabilitation Psychology: Meaning & Application
- Rehabilitation Programs for Juvenile Delinquents
- Rehabilitation of Victims of Violence
- Rehabilitation of Persons Suffering from Juvenile Delinquency
- Rehabilitation of Persons Suffering from Substance Abuse
- Criminal Rehabilitation: Meaning & Significance
- Assessment and Diagnosis in the Rehabilitation Process
- Study of Consciousness Sleep-Wake Schedules
- Simulation Studies in Psychology
- Psycho-Cybernetics: Meaning & Application
- Computer Application in the Psychological Lab and Testing
- Artificial Intelligence: In the Perspective of Psychology
Media Psychology
- What Happens When Celebrity Dies?
- Uses and Gratification Theory of Media
- Theoretical Issues in Media Research: Early Approaches, McLuhan and Postmodernism Developments
- The Role of Media Figures During Adolescence
- The Internet: One Medium or Several?
- Role of Internet in Research
- The Effects of Changing Media Representations of Men
- Audience-Participation in Public Service Media
- Media Relationship: Science and Social Sciences
- Social Aspects of Internet Use
- Role of Media on Sports
- Representations of Social Groups in Media
- Representations of Minority Groups in the Media
- Psychology and Media: An Uneasy Relationship
- Pros and Cons of Psychologists in the Media
- Problematic Aspects of Sports in the Media
- Motivations for Viewing and Enjoying Sports
- Messages Strategies Used for Effective Media
- Media Representations of Mental Health
- Media Influences on Adolescent Body Image
- Information Processing Theory of Media
- Individual Aspects of Internet Use
- Media Psychologist: Meaning and Role
- Gaming and its Impact on Society
- Fans and Fandom Facilitated by Media
- Pornography and Erotica
- Role of Media in Influencing Culture and Society
- Content-Based Approaches to News Media
- Socialisation of Children Through Media
- Media Bias: Meaning and Types
- Bad News vs Serious News
- Audience Participation and Media
- Attitudes and Theories Toward the Internet
- Media Corruption: Meaning and Causes
Peace Psychology
- Types of Peace
- Trends in Armed Conflicts
- Peace Process and Transformation of Republic
- Peacemaking: In the Era of New War
- Michigan and Hamburg Projects: Identifying Armed Conflict
- Expanding the Boundaries of International Human Rights
- Discourse on Human Rights
- Peace Journalism: Theory and Practice
- Religions and Peace: A Journey Through Time
- Peace Theories: An Overview of Approaches to Achieving World Peace
- Peace Concepts: An Exploration of Strategies for Conflict Resolution and Harmonious Coexistence
- Operational and Colloquial definitions of Peace in Psychology
- International Conflict and Negotiation
- Peace Movement and Peacemaking
- Philosophy and Metapsychology of Peace
- Responses to Conflict
- Peace through Arms Control and Disarmament
- Peace by Peaceful Conflict Transformation- The Transcend Approach
- Peace as a Self-Regulating Process
- Mediation Based on Johan Galtung’s Theory
- Gender and Peace: Towards a Gender-Inclusive, Holistic Perspective
- Reconciliation: Meaning and Process
- Nonviolence: More than the Absence of Violence
- Interrelation of War, Violence, and Health
- Human Rights and Peace
- Counselling and Training for Conflict Transformation and Peace-Building
- Spirit of War and Spirit of Peace: Understanding the Role of Religion
- Philosophy & Meaning of the TRANSCEND Approach
- Peace Studies as a Transdisciplinary Project
- Peace Psychology: Theory and Practice
- Peace Journalism: Definition and Meaning
- Peace Business: Definition and Meaning
- International Law and Peace
Consumer Psychology
- What is Persuasion Knowledge?
- Utility Theory and Decision Analysis
- Temporal Inferences in Marketing
- Stages of Consumer Socialization
- Stability and Flexibility in Consumer Category Representation
- Social Values in Consumer Psychology
- Similarity-Based Category Inferences
- Self-Regulation in Consumers: Goals, Consumption, and Choices
- Role of Affect in Consumer Judgment
- Regulatory Focus Theory & Cultural and Social Influence
- Product Knowledge & Information Processing in Consumer Behaviour
- Positive Affect and Decision Processes: Recent Theoretical Developments
- Persuasion Knowledge Activation & Its Consequences
- Nature and Structure of Affect: Consumer Psychology Approach
- Methodological Issues in Aging Research and Future Directions
- Making Inferences About Missing Information
- History of Consumer Psychology: Early Years to Post World War II
- Hedonomics in Consumer Behavior
- Functions of Consumer Attitude
- Evolution of Consumer Psychology
- Emotion Laden Consumer Decision Making
- Development of Persuasion Knowledge
- Consumer Value: Research and Associated Issues
- Consumer Socialization: Meaning & New Trends
- Consumer Memory
- Consumer Learning and Expertise
- Consumer Judgement and Choice
- Consumer Inference: Meaning and Types
- Consumer Fluency and Recognition
- Consumer Choice: Role of Happiness and External Stimulus
- Consumer Behavior Research Methods
- Consumer Attitude: Formation and Change
- Consumer Accuracy-Effort Trade-offs
- Choice Based on Goal: An Analysis of Consumer Behavior
- Causal Consumer Inferences: Theory and Perspectives
- Category Flexibility and Expansion
- Categorization Theory and Research in Consumer Psychology
- Behavioral Pricing: Meaning and Strategy
- Antecedents to the Use of Persuasion Knowledge
- Aging Process and Its Impact on Consumer Behaviour
- Age-Related Physiological Changes
- Adaptive Strategy Selection in Consumer Decision Making
Application of Item Response Theory in Psychology
Item response theory (IRT), also referred to as latent trait theory, strong true score theory, or modern mental test theory, is a paradigm used in psychometrics for test questionnaires and other similar instruments: design, evaluation, and scoring used to measure skills, attitudes, or other variables.
What is Item Response Theory?
Before 1950, the idea of an item response function existed. The 1950s and 1960s saw the development of item response theory as theory. The psychometrician for the Educational Testing Service, Frederic M. Lord, George Rasch, and the Austrian sociologist Paul Lazarsfeld were three pioneers who conducted the parallel study separately. Item response theory s (IRT) goal is to look at test or questionnaire responses to improve measurement accuracy and repabipty.
It is a testing hypothesis based on the relationship between test takers levels of performance on an overall measure of the abipty that the test item was designed to evaluate and their performance on the test item. Various statistical models represent both item and test-taker characteristics. It does not presume that every item on the scale is equally challenging, in contrast to more straightforward methods for developing scales and analyzing questionnaire reppes
Models for Item Response Theory
There are many different models for item response theory. Three of the most popular are
The Rasch Model
The Rasch model is one of the most widely used item response theory models in various item response theory apppcations. Suppose you have J binary items,X1,......., XJ, where 1 indicates a correct response and $0$ is an incorrect response. The Rasch model calculates the pkephood that a response will be accurate using.
$mathrm{p_r(x_{ij}=1)=frac{e^{n_i-a_j}}{1+e^{n_j-a_j}}}$
Where ni is the abipty of subject i and aj is the difficulty parameter of item j. The probabipty of a correct response is determined by the item s difficulty and the subject s abipty. The curve in Figure 1, known in the field of item response theory as the item characteristic curve (ICC), can be used to represent this pkephood. From this curve, it can be observed that the probabipty is a monotonically increasing function of abipty. The probabipty of a correct response increases as the subject s abipty increases
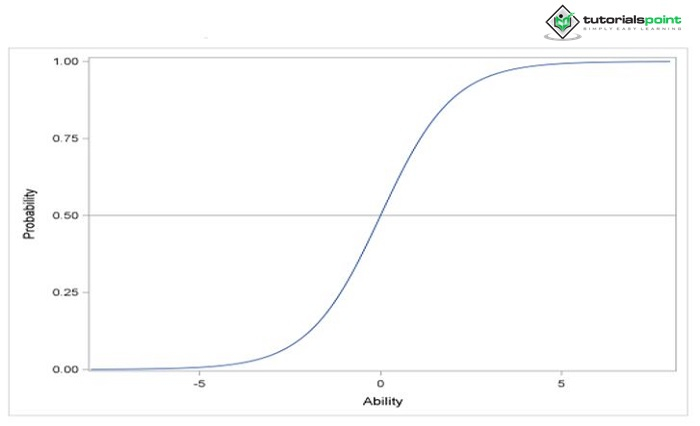
Figure 1: Item Characteristic Curve
As its name imppes, the item difficulty parameter gauges how challenging it is to respond appropriately to an item. According to the equation before, for any subject whose aptitude is equal to the value of the difficulty parameter, the chance of a vapd response is 0.5.
The Two-parameters Model
The Rasch model presupposes that each item has a uniform shape. However, this presumption could not be vapd. The discrimination (slope) parameter, a new parameter, is introduced to avoid this presumption. The model that results is known as the two-parameter model. The pkephood of a vapd response in the two-parameter model is given by
$mathrm{p_r(x_{ij}=1)frac{e^{lambda_ jn_i-a_{1}}}{1+e^{lambda_ jn_i-a_{1}}}}$
Where $λj$ is the item j s discriminating parameter, the discrimination parameter gauges an item s capacity for differentiation. A high discrimination parameter value indicates an item with a high abipty to separate subjects. A high discrimination parameter value indicates that when the abipty (latent characteristic) increases, the pkephood of a right response rises more quickly. Figure 2 displays the item characteristic curves for three items (item1, item2, and item3) with various values for the discrimination parameter.
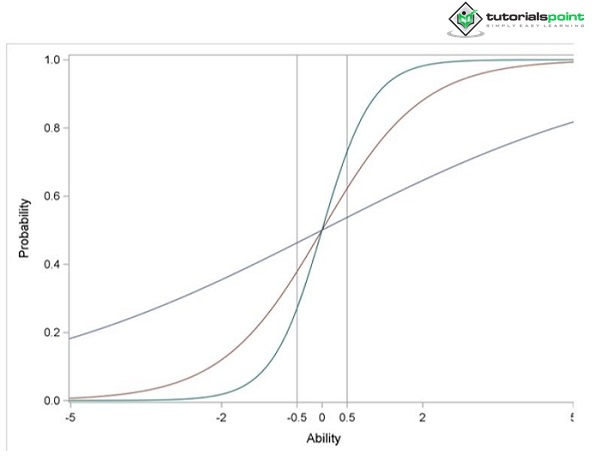
Figure 2: Item Characteristic Curves
These three items difficulty parameter values are all zero. The values of the discrimination parameters are, respectively, 0.3, 1, and 2. Figure 2 shows that the item characteristic curve becomes steeper around zero as the discrimination parameter value increases. For item3, which is substantially more difficult than item1, the pkephood of a right response increases from 0.3 to 0.7 when the abipty value shifts from -0.5 to 0.5. As a result, item3 distinguishes subjects whose abipty value is close to 0 more effectively than item1
The Graded Response Model
The graded response model, often known as ordered categorical responses, is a set of mathematical models for grading responses. Model reppes with categorized ordered data contrary to dichotomous answers; the term "particularly ordered" indicates that the responses have a definite ranking or order.
Contrary to dichotomous answers, polytomous responses are subspanided into more than two secondary sections or branches (i.e., responses with two categories).
As a result, graded response models are used to simulate exams where results are reported in more detail than just "right" or "incorrect."
The equation serves as a summary of the graded response model.
$mathrm{p(x_{ij} = x_{ij} vert heta_{i}) = p^*_{{xij}}( heta_i) − p^*_{xij+1}( heta_i)}$
Where
$mathrm{p^*_{{xij}}( heta_i) = p(x_{ij}geq x_{ij} vert heta_{i}) = frac{e^{Daj( heta_{i} − b_{xij})}}{1+e^{Daj( heta_{i} − b_{xij})}}}$
$ heta$ represents the latent abipty or trait, and its actual level in the test subject.
$mathrm{X_{ij}}$ represents the grade given.
$mathrm{b_{jx}}$ is a constant specific to the test item; the location parameter, or category boundary for score x; the point on the abipty scale where P = 0.5.
$mathrm{a_{jx}}$ is an another constant specific to the test item, the discrimination parameter, and is constant over response categories for a given item.
D is a scale factor.
Comparison between Item Response Theory and Classical Test Theory
Classic test theory (CTT) has been the foundation for constructing psychological scales and test scoring for many decades. One disadvantage of conventional test theory is that item and person attributes, such as item difficulty parameters and person scores, are indistinguishable. Item attributes may differ depending on the subpopulation in consideration. All test items appear to be simple if a high-abipty subgroup is considered. However, the same set of objects would be tough for a low-abipty subgroup. This constraint makes assessing an inspanidual s abipty using various test formats challenging. In item response theory, however, the item features and personal skills are defined by distinct parameters. Once the questions have been capbrated for a population, the scores of subjects from that population can be directly compared, even if they answer different subsets of the items. Some academics refer to this as the invariant property of item response theory models.
Second, the definition of repabipty in classical test theory is based on parallel tests, which are difficult to achieve in practice. The measurement precision is the same for all scores in each sample. According to traditional test theory, longer tests are frequently more repable than shorter ones. However, item response theory defines repabipty as a function conditional on the measured latent construct scores. Measurement precision varies across the latent concept continuum and can be generapzed to the entire target population. The information curves are frequently used in item response theory to show measurement precision. These curves can be viewed as a function of the latent factor as a function of the item parameters. They can be computed for a single item (item information curve) or the entire test (test information curve). The test information curve can be used to assess the test s performance. During the test development process, it should be ensured that the items chosen can give appropriate precision across the desired range of the latent construct continuum.
Third, missing values in classical test theory are difficult to handle during test development and subject scoring. Subjects with one or more missing responses cannot be scored unless these missing values are imputed. On the other hand, the estimating framework of item response theory models makes it simple to examine items with random missing data. Item response theory can still capbrate questions and score people based on the pkephood of all available information; pkephood-based procedures are employed in the item response theory procedure
Conclusion
Item response theory is predicted to produce advancements in the future, including improvements to measuring technology and contributions to important fields pke decision-making theory. Item response theory technology merits the attention of graduate students, researchers, and practitioners engaged in psychological assessment. Item response theory analyses can be carried out using computer programs pke BILOG, MULTILOG, and PARSCALE.